DECLARE @date date = '2024-10-30'
SELECT (day(datediff(d,0,@date)/7*7)-1)/7+1output:
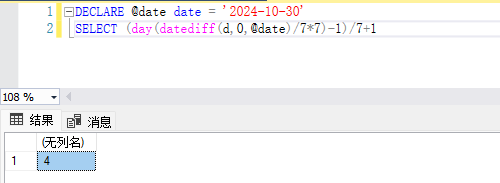
DECLARE @date date = '2024-10-30'
SELECT (day(datediff(d,0,@date)/7*7)-1)/7+1output:
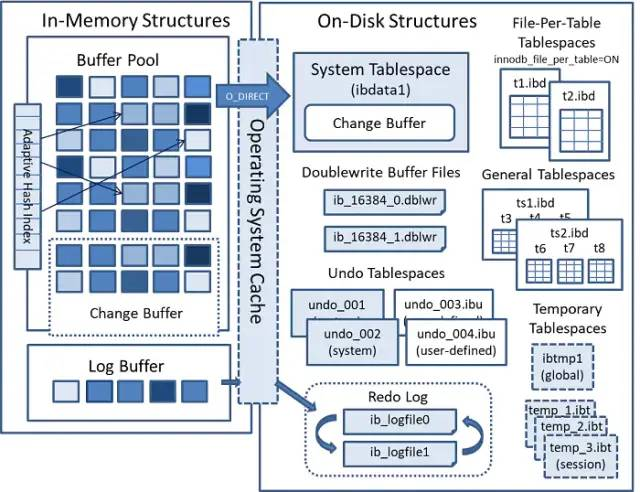
innodb_buffer_pool_size,正常推荐设置50%-75%的系统内存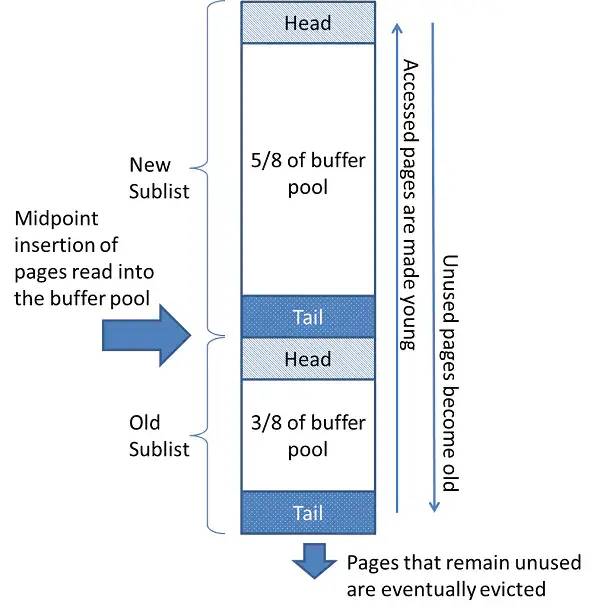
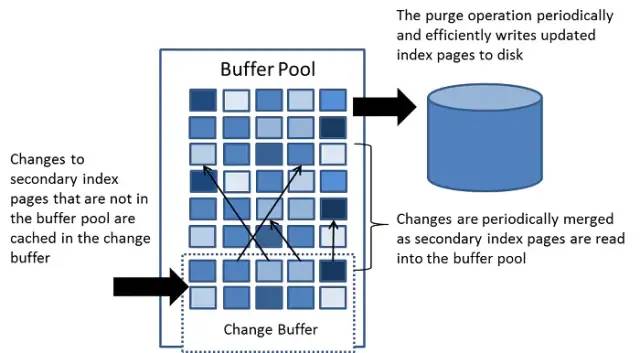
一个事务最多分配4个undo logs,每个都是下面的操作类型之一:
表级锁,用于指示事务稍后在表里需要哪种类型的锁(共享或排他)
SELECT … FOR SHARE设置IS锁,SELECT … FOR UPDATE设置IX锁
事务在能获取表里行的共享锁之前,必须先获取表的IS锁或更强的锁
事务在能获取表里行的排他锁之前,必须先获取表的IX锁或更强的锁
在索引记录上的锁
记录锁始终锁定索引记录,即使表上没有定义索引。这种情况下,InnoDB会创建一个隐式的聚簇索引,使用这个索引锁定记录
索引记录间隙之间的锁,或者第一个索引记录之前或最后一个索引记录之后的间隙的锁
e.g. SELECT c1 FROM t WHERE c1 BETWEEN 10 and 20 FOR UPDATE;
会阻止其他事务插入15的值到t.c1列,而不用管在这个列中有没有这个值
对于使用唯一索引搜索唯一行的语句,不需要间隙锁。e.g.列id有唯一索引,下面这语句只对id=100的行使用索引记录锁,其他会话是否在前面的间隙中插入行并不重要
SELECT * FROM child WHERE id = 100;如果id没有被索引,或者没有唯一索引,则语句会锁定前面的间隙
InnoDB的间隙锁是“纯抑制性的”,它的唯一目的是阻止其他事务插入到这个间隙,间隙锁可以共存,共享和排他间隙锁没有差别
间隙锁是可以被禁用的,如果被禁用可能会导致幻读问题,因为其他session可以将新行插入间隙
是索引记录上的记录锁和索引记录之前间隙上的间隙锁的组合
如果一个session在索引的记录R上有一个共享或排他锁,则另一个session不能在索引顺序中紧靠R之前的间隙中立即插入新的索引记录
假设索引包含值10,11,13,20。那么这个索引上可能的next-key锁包含下面的几种间隔
(negative infinity, 10]
(10, 11]
(11, 13]
(13, 20]
(20, positive infinity)默认InnoDB运行在REPEATABLE READ事务隔离级别。这种情况下,InnoDB使用next-key锁来进行搜索和索引扫描
行插入之前通过INSERT操作设置的一种间隙锁。此锁表示插入的意图,如果插入到同一个索引间隙的多个事务不在间隙的同个位置插入,则它们无需互相等待
假设有索引记录值4和7。不同的事务尝试插入5和6,在获得插入行的排它锁之前,每个事务都会使用插入意向锁锁住4和7之间的间隙,但因为行不冲突而不会互相阻塞
e.g. 客户端A创建一个表,包含了两个索引记录90和102,然后启动一个事务,对ID大于100的索引记录进行排它锁。这个排它锁包含了记录102前面的间隙
mysql> CREATE TABLE child (id int(11) NOT NULL, PRIMARY KEY(id)) ENGINE=InnoDB;
mysql> INSERT INTO child (id) values (90),(102);
mysql> START TRANSACTION;
mysql> SELECT * FROM child WHERE id > 100 FOR UPDATE;
+-----+
| id |
+-----+
| 102 |
+-----+客户端B开始一个插入记录到间隙的事务。这个事务在它等待获取排它锁时接受插入意向锁
mysql> START TRANSACTION;
mysql> INSERT INTO child (id) VALUES (101);是一种特殊的表锁,事务插入有AUTO_INCREMENT列的表的时候使用。如果一个事务正在向表插入值,任何其他事务在插入这个表的时候都必须等待,以便第一个事务接收连续的主键值
e.g. 可重复读 VS. 读已提交
CREATE TABLE t (a INT NOT NULL, b INT) ENGINE = InnoDB;
INSERT INTO t VALUES (1,2),(2,3),(3,2),(4,3),(5,2);
COMMIT;这种情况下,表没有索引,因此搜索和索引扫描时使用隐式的聚簇索引来进行记录锁定
### Session A 执行更新语句
START TRANSACTION;
UPDATE t SET b = 5 WHERE b = 3;
### Session B 在sessionA之后执行
UPDATE t SET b = 4 WHERE b = 2;在InnoDB执行每个更新的时候,它先为每一行获取一个排它锁,然后决定是否修改它。如果InnoDB不修改这行,它就会释放这个锁。否则InnoDB持有锁,直到事务结束。
当使用默认的可重复读级别时,第一个UPDATE在它读取的每行上获取x锁,不释放它们中的任何一个:
x-lock(1,2); retain x-lock
x-lock(2,3); update(2,3) to (2,5); retain x-lock
x-lock(3,2); retain x-lock
x-lock(4,3); update(4,3) to (4,5); retain x-lock
x-lock(5,2); retain x-lock
第二个UPDATE在尝试获取任何锁的时候会立即阻塞(因为第一个更新在所有行上保留了锁),并且在第一次UPDATE提交或回滚之前不会继续
x-lock(1,2); block and wait for first UPDATE to commit or roll back
如果使用READ COMMITTED,第一个UPDATE会在每行上获取一个x锁,并释放这些不修改的行
x-lock(1,2); unlock(1,2)
x-lock(2,3); update(2,3) to (2,5); retain x-lock
x-lock(3,2); unlock(3,2)
x-lock(4,3); update(4,3) to (4,5); retain x-lock
x-lock(5,2); unlock(5,2)
对于第二个UPDATE,InnoDB执行“半一致”读,将读取的每一行的最新版本返回给MySQL,以便MySQL可以确定该行是否匹配UPDATE的WHERE条件
x-lock(1,2); update(1,2) to (1,4); retain x-lock
x-lock(2,3); unlock(2,3)
x-lock(3,2); update(3,2) to (3,4); retain x-lock
x-lock(4,3); unlock(4,3)
x-lock(5,2); update(5,2) to (5,4); retain x-lock
然后如果WHERE条件包含索引列,并且InnoDB使用这个索引,那么在获取和保留记录锁的时候只考虑索引列。
在下面这个例子,第一个UPDATE在b=2的每一行上获取并持有x锁,第二个UPDATE当它尝试获取相同记录上的x锁的时候会阻塞,因为它也使用列b上定义的索引
CREATE TABLE t (a INT NOT NULL, b INT, c INT, INDEX (b)) ENGINE = InnoDB;
INSERT INTO t VALUES (1,2,3),(2,2,4);
COMMIT;
### Session A
START TRANSACTION;
UPDATE t SET b = 3 WHERE b = 2 AND c = 3;
### Session B
UPDATE t SET b = 4 WHERE b = 2 AND c = 4;InnoDB中,所有用户活动都是在事务里。如果autocommit模式启用,每个SQL语句都会形成它自己的事务。默认MySQL为每个新连接启动session的时候,会设置autocommit为启用,所以MySQL会在每个SQL语句没有返回错误之后进行一次提交。如果语句返回错误,会依赖具体的错误进行提交或回滚
对于autocommit启用的session,可以通过START TRANSACTION或BEGIN语句开始事务,COMMIT或ROLLBACK结束事务。
如果在一个session里通过SET autocommit = 0来禁用autocommit,那么这个session会始终有一个打开的事务。COMMIT或ROLLBACK语句会结束当前事务,启动新的事务。
如果session禁用了autocommit,没有强制提交最后的事务,那么这事务会被回滚。
一致读意味着InnoDB使用多版本控制呈现数据库在某个时间点的一个快照。查询可以看到在这个时间点之前其他事务已提交的更改,不能看得到之后或未提交的事务。
如果事务隔离级别是默认的REPEATABLE READ,在相同事务里的所有一致读都会读取这个事务第一次读的时候建立的快照。可以通过提交当前事务并在之后发出新的查询来得到新的快照
对于READ COMMITTED隔离级别,每个事务里的一致读都会设置并读取它自己的新快照
一致读是InnoDB在READ COMMITTED和REPEATABLE READ隔离级别下处理SELECT语句的默认模式。一致读不会在它访问的表上设置任何锁,因此其他session可以同时自由修改这些表
数据库的快照状态应用于事务里的SELECT语句,不一定应用于DML语句。如果插入或修改某些行然后提交该事务,则从另一个并发的可重复读事务会影响到这些刚提交的行,尽管这session查询不到它们。如果某个事务确实更新或删除了不同事务提交的行,则这些更改对当前事务是可见的。
例子(其他session提交记录,原session查询不到,可以删除):
#sessionA
select count(name) from child where name = 'hello100';
### 返回0行
#sessionB插入两行并提交
insert into child(id,name) values(100, 'hello100');
insert into child(id,name) values(101, 'hello100');
#sessionA统计,返回0行
select count(name) from child where name = 'hello100';
#sessionA删除,尽管查询不到,但可以删除2行
delete from child where name = 'hello100';
### Query OK, 2 rows affected (0.00 sec)可以通过提交事务,然后执行SELECT或START TRANSACTION WITH CONSISTENT SNAPSHOT来更新时间点。这就是多版本并发控制
下面的例子,sessionA只在B提交了插入,且A已提交后,才能看到B插入的记录
Session A Session B
SET autocommit=0; SET autocommit=0;
time
| SELECT * FROM t;
| empty set
| INSERT INTO t VALUES (1, 2);
|
v SELECT * FROM t;
empty set
COMMIT;
SELECT * FROM t;
empty set
COMMIT;
SELECT * FROM t;
---------------------
| 1 | 2 |
---------------------如果想看到数据库的最新状态,那么要使用READ COMMITTED隔离级别,或者锁定读:
SELECT * FROM t FOR SHARE;
读已提交隔离级别,一个事务里的每个一致读都会设置并读取它自己的新快照。对于FOR SHARE,SELECT一直阻塞直到包含最新行的事务结束
锁定读,UPDATE或者DELETE通常会在SQL语句处理的过程中对每个被扫描到的索引记录设置记录锁。它不管语句中的WHERE条件是否会排除掉行。InnoDB不会记得准确的WHERE条件,只知道哪部分索引范围被扫描。
如果搜索中使用了二级索引,并且索引记录锁被设置为排他的,InnoDB也会检索出相应的聚簇索引记录并对它们设置锁。
如果没有索引适合执行语句,那么MySQL必须扫描整个表来处理语句,表的每一行都会被锁定,从而也会阻塞其他用户插入到这个表中。所以创建好的索引,让查询不会扫描超过需要的行是很重要的。
因为不同的事务持有对方需要的锁,导致这些事务不能执行下去。由于每个事务都在等待资源变成可用,都不会释放它持有的锁。
可能出现的场景:多个事务以不同的顺序锁定多个表中的行(通过类似这样的语句:UPDATE或SELECT … FOR UPDATE),锁定范围索引记录和间隙,每个事务因为时间的原因只获取一部分锁。
为了减少死锁的可能,
死锁的可能不会被隔离级别影响,因为隔离级别只改变了读操作的行为,而死锁是因为写操作。
InnoDB是一个多版本的存储引擎。它持有被更改过的行的旧版本信息,以支持例如并发和回滚这样的事务特性。这个信息存储在undo表空间里面一个叫rollback segment的数据结构中。InnoDB使用回滚段里的信息来执行事务回滚里面的undo操作。它还使用这信息来构建更早版本的行用于实现一致性读。
InnoDB内部在数据库里存储的每个行里添加了三个字段:
回滚段里的Undo日志被分成了插入和更新的undo日志。插入的undo日志只在事务回滚的时候需要,可以在事务提交的时候立即丢弃掉。更新的undo日志也用于一致性读,但只有在不存在InnoDB已为其分配快照的事务时才能丢弃。在一致性读中,快照需要更新的undo日志中的信息用于构建数据库行的早期版本。
建议定期提交事务,包括仅发出一致性读的事务。否则InnoDB不能从更新的undo日志里丢弃数据,这样回滚段可能会增长得太大,充满它驻留的整个undo表空间。
回滚段里的undo日志记录的物理大小通常比相应的插入或更新行更小。可以使用这个信息来记录回滚段需要的空间。
在InnoDB多版本控制方案中,当使用SQL语句删除的时候,该行并不会立即从数据库中物理删除。InnoDB仅在丢弃为删除而写入的更新undo日志的时候,才会物理删除相应的行和索引记录。
InnoDB 多版本并发控制(MVCC)对待二级索引不同于聚簇索引。聚簇索引中的记录会就地更新,其隐藏的系统列指向undo日志项,从中可以重构早期版本的记录。二级索引不包含隐藏的系统列,也不进行就地更新。
更新二级索引列时,旧的二级索引被删除标记,新记录被插入,删除标记的记录最终被清除。当二级索引记录被删除标记,或者二级索引页被更新的一个事务更新时,InnoDB会在聚簇索引中查找数据库记录。在聚簇索引中,检查记录的DB_TRX_ID,如果在读取事务启动后修改了记录,则从undo日志里检索出记录的正确版本。
如果二级索引记录被标记为删除,或者二级索引页被新的事务更新,覆盖索引记录就不会被使用。InnoDB不会从索引结构里返回值,而是会从聚簇索引里查找记录
幻读,同一个事务里连续执行两次同样的SQL,可能导致不同结果的问题。第二次sql语句可能会返回之前不存在的行。
select ... lock in share mode
select ... for update
insert
update
delete在RR级别:
binlog包含描述数据库更改(如表创建操作或表数据变更)的“事件”。除非使用基于行的日志记录,否则它还包含可能已进行更改的语句的事件(例如不匹配任何行的删除)。binlog还包含更新数据时每个语句花费了多长的时间。
类型
insert into [标明](列1,列2....) exec [存储过程名] [存储过程参数]
exec sp_rename '[表名].[列名]','[新列名]'注意:单引号不可省略。
C# 中有许多内存数据库供开发人员使用,以下是几个常用的内存数据库:
Redis 是一个开源的 In-Memory 数据库系统,支持多种数据类型。可以用来做缓存、消息队列及分布式锁等。
SQLite 是一个轻量级的数据库系统,支持 ACID 事务,使用内存数据库时,会将数据存储在内存中而不是硬盘上。
Apache Ignite 是一个分布式的高可用性内存数据库,提供分布式事务、分布式 SQL 查询、分布式计算等功能。
这是一个基于内存的事务处理引擎,可以明显提升 SQL Server 数据库的性能,支持多种 OLTP 需求场景。
RavenDB 是一个基于 NoSQL 的文档数据库,具有内存数据库的优点,并支持强大的多租户特性。
MongoDB 是一个开源的文档数据库,支持各种丰富的查询语言,并且具有内存数据库的优点,使得它可以处理大量的数据。
这些内存数据库各自有优点和适用场景,选择哪一个取决于具体的应用需求和使用方案。
SQL Server 2019 支持正则表达式,您可以使用LIKE运算符与正则表达式元字符结合使用来匹配模式。
以下是一个示例,用于使用正则表达式从表中选择具有特定字符模式的行:
假设您有一个名为employees的表,其中包含full_name列。您可以使用以下查询来选择full_name列中以字母“a”开头,并以字母“y”结尾的所有行:
SELECT full_name
FROM employees
WHERE full_name LIKE 'a%y';在上面的查询中,%是一个SQL通配符,代表零个或多个任意字符。因此,查询选择了full_name列中以字母“a”开头,并以字母“y”结尾的所有行。 此查询仅匹配以字母“a”开头,并以字母“y”结尾的字符串,而不是包含任意位置的字母“a”和“y”的字符串。
如果要使用更复杂的模式,可以将通配符与正则表达式结合使用。例如,要选择所有包含至少一个数字的full_name,您可以执行以下查询:
SELECT full_name
FROM employees
WHERE full_name LIKE '%[0-9]%';在上面的查询中,[0-9]是一个正则表达式字符集,代表任何数字字符。因此,查询选择了full_name列中包含至少一个数字的所有行。
请注意,正则表达式功能在不同数据库管理系统和版本之间可能会有所不同。如果您使用的是不同的版本或数据库,建议您查看相关文档以了解它们支持的SQL语言和函数。
在 SQL Server 中,可以使用 JSON_VALUE 函数查询 JSON 数据的特定值,使用 JSON_QUERY 函数查询 JSON 数据的特定对象,使用 JSON_MODIFY 函数更新 JSON 数据。
以下是一些示例:
1. 查询特定 JSON 字段的值:
SELECT JSON_VALUE(json_column, '$.field_name')
FROM table_name;2. 查询 JSON 对象并返回整个 JSON 字符串:
SELECT JSON_QUERY(json_column)
FROM table_name;3. 查询 JSON 对象中的特定字段:
SELECT JSON_QUERY(json_column, '$.field_name')
FROM table_name;4. 在 JSON 对象中更新现有值:
UPDATE table_name
SET json_column = JSON_MODIFY(json_column, '$.field_name', 'new_value')
WHERE some_condition;SQL Server 中的 CROSS APPLY 类似于 INNER JOIN,但 CROSS APPLY一般用于连接带参表值函数和带参数子查询;而 OUTER APPLY 则类似于 LEFT JOIN,也是用于连接带参表值函数和带参数子查询 。
以下示例假定数据库中存在以下表和表值函数:
| 对象 | 列名 |
|---|---|
| Departments | DeptID、DivisionID、DeptName、DeptMgrID |
| EmpMgr | MgrID、EmpID |
| Employees | EmpID、EmpLastName、EmpFirstName、EmpSalary |
| GetReports(MgrID) | EmpID、EmpLastName、EmpSalary |
GetReports 表值函数返回直接或间接报告给指定 MgrID 的所有员工的列表。
该示例使用 CROSS APPLY 返回所有部门和部门中的所有员工。 如果某个部门没有任何员工,则将不返回该部门的任何行。
SELECT DeptID, DeptName, DeptMgrID, EmpID, EmpLastName, EmpSalary
FROM Departments d
CROSS APPLY dbo.GetReports(d.DeptMgrID);如果您希望查询为那些没有员工的部门生成行(这将为 EmpID、EmpLastName 和 EmpSalary 列生成 Null 值),请改用 OUTER APPLY。
SELECT DeptID, DeptName, DeptMgrID, EmpID, EmpLastName, EmpSalary
FROM Departments d
OUTER APPLY dbo.GetReports(d.DeptMgrID);MySQL 8.0.18 稳定版(GA)已于14/10正式发布,Hash Join 也如期而至。
快速浏览一下这个版本的亮点!
Hash Join 不需要任何索引来执行,并且在大多数情况下比当前的块嵌套循环算法更有效。
EXPLAIN ANALYZE 将运行查询,然后生成 EXPLAIN 输出,以及有关优化程序估计如何与实际执行相匹配的其他信息。
为 CREATE USER, ALTER USER和 SET PASSWORD语句添加了语法,以生成强随机密码,并将其作为结果返回给客户端。
添加的语法是:
CREATE USER user IDENTIFIED BY RANDOM PASSWORD;
ALTER USER user IDENTIFIED BY RANDOM PASSWORD;
SET PASSWORD [FOR user] TO RANDOM;group_replication_exit_state_action 增加了 OFFLINE_MODE 模式,用于指定当服务器无意离开群组时群组复制的行为。
OFFLINE_MODE 行为将关闭所有连接,并禁止非 CONNECTION_ADMIN 或 SUPER 权限的用户建立新连接,否则它的行为类似于现有 READ_ONLY 模式。
该选项在 InnoDB 空闲时控制写 IOP。目的是减少写 IO,以延长闪存的寿命。
此外,还有很多内部细节的改进,详细请访问:
https://dev.mysql.com/doc/relnotes/mysql/8.0/en/news-8-0-18.html
允许将显式值插入到表的标识列中。
SET IDENTITY_INSERT [ [ database_name . ] schema_name . ] table_name { ON | OFF }|
参数名
|
简要说明
|
|---|---|
| database_name | 指定的表所在的数据库的名称。 |
| schema_name | 表所属架构的名称。 |
| table_name | 包含标识列的表的名称。 |
任何时候,一个会话中只有一个表的 IDENTITY_INSERT 属性可以设置为 ON。 如果某个表已将此属性设置为 ON,则对另一个表发出 SET IDENTITY_INSERT ON 语句时,SQL Server 将返回一个错误信息,指出 SET IDENTITY_INSERT 已设置为 ON,并报告已将其属性设置为 ON 的表。
如果插入值大于表的当前标识值,则 SQL Server 自动将新插入值作为当前标识值使用。
SET IDENTITY_INSERT 的设置是在执行或运行时设置的,而不是在分析时设置的。
用户必须拥有表,或对表具有 ALTER 权限。
下面的示例将创建一个包含标识列的表,并说明如何使用 SET IDENTITY_INSERT 设置来填充由 DELETE 语句导致的标识值中的空隙。
USE AdventureWorks2012;
GO
-- Create tool table.
CREATE TABLE dbo.Tool(
ID INT IDENTITY NOT NULL PRIMARY KEY,
Name VARCHAR(40) NOT NULL
);
GO
-- Inserting values into products table.
INSERT INTO dbo.Tool(Name)
VALUES ('Screwdriver')
, ('Hammer')
, ('Saw')
, ('Shovel');
GO
-- Create a gap in the identity values.
DELETE dbo.Tool
WHERE Name = 'Saw';
GO
SELECT *
FROM dbo.Tool;
GO
-- Try to insert an explicit ID value of 3;
-- should return an error:
-- An explicit value for the identity column in table 'AdventureWorks2012.dbo.Tool' can only be specified when a column list is used and IDENTITY_INSERT is ON.
INSERT INTO dbo.Tool (ID, Name) VALUES (3, 'Garden shovel');
GO
-- SET IDENTITY_INSERT to ON.
SET IDENTITY_INSERT dbo.Tool ON;
GO
-- Try to insert an explicit ID value of 3.
INSERT INTO dbo.Tool (ID, Name) VALUES (3, 'Garden shovel');
GO
SELECT *
FROM dbo.Tool;
GO
-- Drop products table.
DROP TABLE dbo.Tool;
GO